Development/ollama: Difference between revisions
No edit summary |
No edit summary |
||
| Line 5: | Line 5: | ||
== Introduction == |
== Introduction == |
||
Ollama is an inferencing framework that provides access to a multitude of powerful, large models and allows |
Ollama is an inferencing framework that provides access to a multitude of powerful, large models and allows |
||
performant access to a variety of accelerators, e.g. from CPUs using AVX-512 to APUs like AMD MI-300A, |
performant access to a variety of accelerators, e.g. from CPUs using AVX-512 to APUs like the AMD MI-300A, |
||
as well as GPUs like multiple NVIDIA H100. |
as well as GPUs like multiple NVIDIA H100. |
||
Installing the inference server Ollama assumes you have root permission to install the server globally for all users |
Installing the inference server Ollama by default assumes you have root permission to install the server globally for all users |
||
into the directory <code>/usr/local/bin</code>. Of course, this is not sensible. |
into the directory <code>/usr/local/bin</code>. Of course, this is '''not''' sensible. |
||
Therefore the clusters provide the [[Environment_Modules|Environment Modules]], |
Therefore the clusters provide the [[Environment_Modules|Environment Modules]] including binaries and libraries for CPU (if available AVX-512), AMD ROCm (if available) and NVIDIA CUDA using: |
||
module load devel/ollama |
module load devel/ollama |
||
| Line 32: | Line 32: | ||
[USERNAME@uc2n520 ~]$ |
[USERNAME@uc2n520 ~]$ |
||
Prior to starting and pulling models, it is a '''good idea''' to allocate a proper [[Workspace]] for the (large) models, a sub-directory and create a soft-link into this directory for Ollama: |
|||
| ⚫ | |||
ws_allocate ollama_models 60 |
|||
mkdir -p /pfs/work7/workspace/scratch/es_rakeller-ollama_models/.ollama/ |
|||
ln -s /pfs/work7/workspace/scratch/es_rakeller-ollama_models/.ollama . |
|||
| ⚫ | |||
module load devel/ollama |
module load devel/ollama |
||
ollama serve & |
|||
From another terminal You may log into the Cluster's login node a second time and install a LLM: |
|||
module load devel/ollama |
|||
export OLLAMA_HOST=uc2n520 |
|||
ollama pull deepseek-r1 |
|||
Of course, You may want to '''locally on Your laptop'''. |
|||
Open another terminal and start the Secure shell using the port forwarding: |
|||
ssh -L 11434:uc2n520:11434 USERNAME@bwunicluster.scc.kit.edu |
|||
Your OTP: 123456 |
|||
Password: |
|||
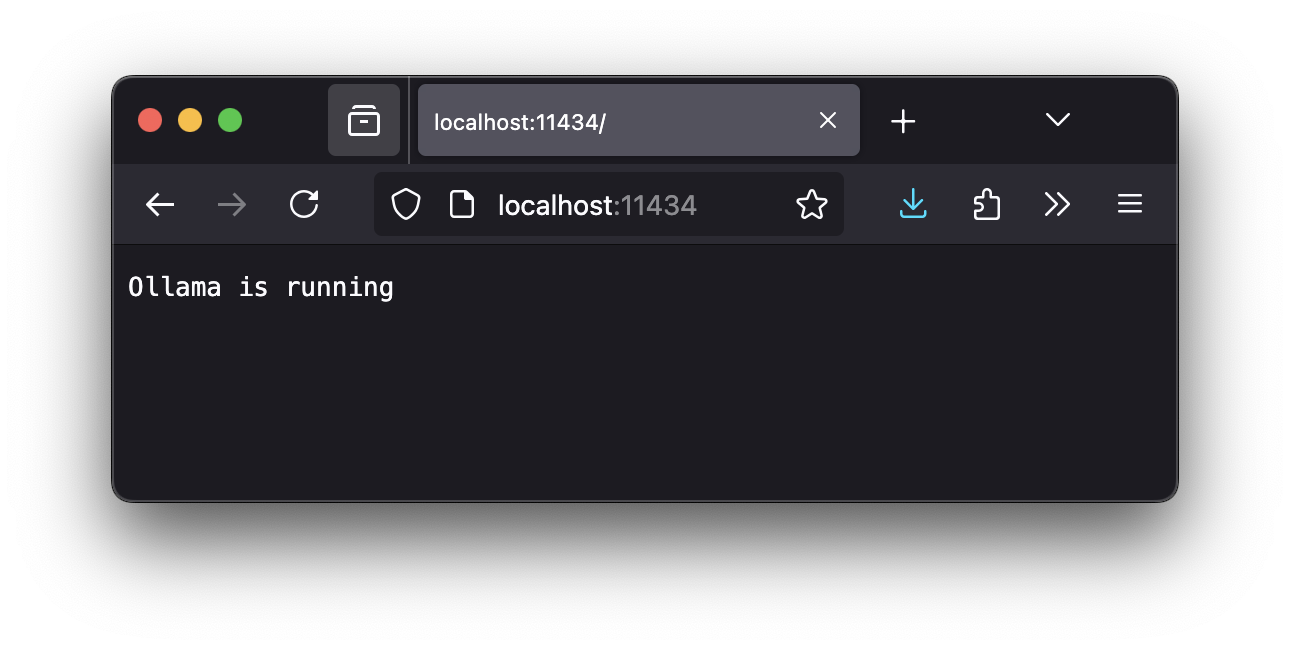
You may check using whether this worked using Your local browser on Your Laptop: |
|||
[[File:firefox_ollama.png]] |
|||
Revision as of 19:42, 11 February 2025
Using LLMs even for inferencing requires large computational resources - currently at best a powerful GPU -- as provided by the bwHPC clusters. This page explains to how to make usage of bwHPC resources, using Ollama as an example to show best practices at work.
Introduction
Ollama is an inferencing framework that provides access to a multitude of powerful, large models and allows performant access to a variety of accelerators, e.g. from CPUs using AVX-512 to APUs like the AMD MI-300A, as well as GPUs like multiple NVIDIA H100.
Installing the inference server Ollama by default assumes you have root permission to install the server globally for all users
into the directory /usr/local/bin. Of course, this is not sensible.
Therefore the clusters provide the Environment Modules including binaries and libraries for CPU (if available AVX-512), AMD ROCm (if available) and NVIDIA CUDA using:
module load devel/ollama
More information is available in Ollamas Github documentation page.
The inference server Ollama opens the well-known port 11434. The compute node's IP is on the internal network, e.g. 10.1.0.101, which is not visible to any outside computer like Your laptop. Therefore we need a way to forward this port on an IP visible to the outside.
Port forwarding
The login nodes of course have externally visible IP addresses, e.g. bwunicluster.scc.kit.edu which get to resolved to one of the multiple login nodes.
Using the Secure shell ssh one may forward a port from the login node to the compute node.
First, we need to allocate a compute node using Slurm. At first You may start with interactively checking out the method in one terminal:
srun --time=00:30:00 --gres=gpu:1 --pty /bin/bash
Please note that on bwUniCluster, You need to provide a partition, here containing a GPU, e.g. for this 30 minute run, we may select --partition=dev_gpu_4, on DACHS --partition=gpu1.
Your Shell's prompt will list the nodes name, e.g. on bwUniCluster node uc2n520:
[USERNAME@uc2n520 ~]$
Prior to starting and pulling models, it is a good idea to allocate a proper Workspace for the (large) models, a sub-directory and create a soft-link into this directory for Ollama:
ws_allocate ollama_models 60 mkdir -p /pfs/work7/workspace/scratch/es_rakeller-ollama_models/.ollama/ ln -s /pfs/work7/workspace/scratch/es_rakeller-ollama_models/.ollama .
Now You may load the Ollama module and start the server on the compute node:
module load devel/ollama ollama serve &
From another terminal You may log into the Cluster's login node a second time and install a LLM:
module load devel/ollama export OLLAMA_HOST=uc2n520 ollama pull deepseek-r1
Of course, You may want to locally on Your laptop. Open another terminal and start the Secure shell using the port forwarding:
ssh -L 11434:uc2n520:11434 USERNAME@bwunicluster.scc.kit.edu Your OTP: 123456 Password:
You may check using whether this worked using Your local browser on Your Laptop: